이 글은 2023 GDSC Sookmyung Core Member Session을 텍스트로 정리한 것입니다. (사실 대본 작성하는 김에 쓴거예요-!!) 영상으로 보고 싶으신 분들은 이 링크를 참고해주세요. 대부분의 내용은 조영호 님의 <객체지향의 사실과 오해>, <오브젝트>, 이일민 님의 <토비의 스프링 vol1>을 참고했습니다.
이번 포스팅에서는 스프링이 객체지향이라는 가치를 어떻게 실천하고, 개발자가 어떻게 비즈니스 로직에만 집중할 수 있도록 도와주는지 살펴보겠습니다.
스프링은 자바 엔터프라이즈 애플리케이션 프레임워크입니다. 애플리케이션 프레임워크는 애플리케이션의 전 과정, 데이터 액세스나 http 요청 응답 매핑, 비즈니스 로직 등을 빠르고 편리하며 효율적으로 진행하는데 목적을 둡니다. 자바 엔터프라이즈 개발은 대규모의 애플리케이션, 데이터 처리 및 데이터베이스 관리, 보안 등의 복잡한 요구사항을 처리할 수 있도록 자바 플랫폼을 기반으로 하는 솔루션을 말합니다. 엔터프라이즈 개발은 기술적인 요구사항과 비즈니스 로직 요구사항의 증가하는 복잡성을 감당할 수 있어야 합니다. 복잡성을 해결하고 뛰어난 성능과 안정적인 시스템을 유지하기 위해서 필요한 것은 성격이 다른 기술적 복잡성과 비즈니스 요구사항의 복잡성을 완전히 분리하는 작업입니다. 이러한 복잡성을 감추고 복잡성을 유연하게 반영할 수 있는 설계를 만들기 위해 스프링은 객체지향 패러다임을 선택했습니다.
사실 복잡성을 분리하려는 시도는 스프링 이전에도 있었습니다. 스프링 전에 자바 엔터프라이즈 진영을 잡고 있던 EJB도 복잡성을 분리하는 시도를 했으나, 정작 비즈니스 로직을 EJB 흐름으로 포함시키기 위해 특정 인터페이스나 클래스를 상속하도록 강제했기 때문에 비즈니스 로직에 프레임워크의 코드가 침투하게 되었습니다. 그 결과 개발자들이 객체지향적인 코드를 작성하지 못하고, 프레임워크 흐름에 따라 동작하는 스크립트성 코드를 짜게 되었고, 로직을 변경할 때 굉장히 큰 고통을 받았다고 합니다. 스프링은 이런 상황에 반기를 들고 진정한 객체지향으로 돌아가자는 움직임에서 시작된 프레임워크입니다.
그래서 스프링이 가장 중시하는 프로그래밍 방식은 POJO입니다. Plain Old Java Object, 순수한 자바 객체를 사용해서 객체지향적인 기법을 최대한 살리는 방법입니다. 스프링 개발자가 비즈니스 로직을 객체지향적으로 작성할 수 있도록 기술적인 복잡성은 스프링이 추상화하는데요, 이것을 지지하는 기술이 IoC 기반의 DI, 서비스 추상화(PSA), 관점 지향 프로그래밍(AOP)입니다.
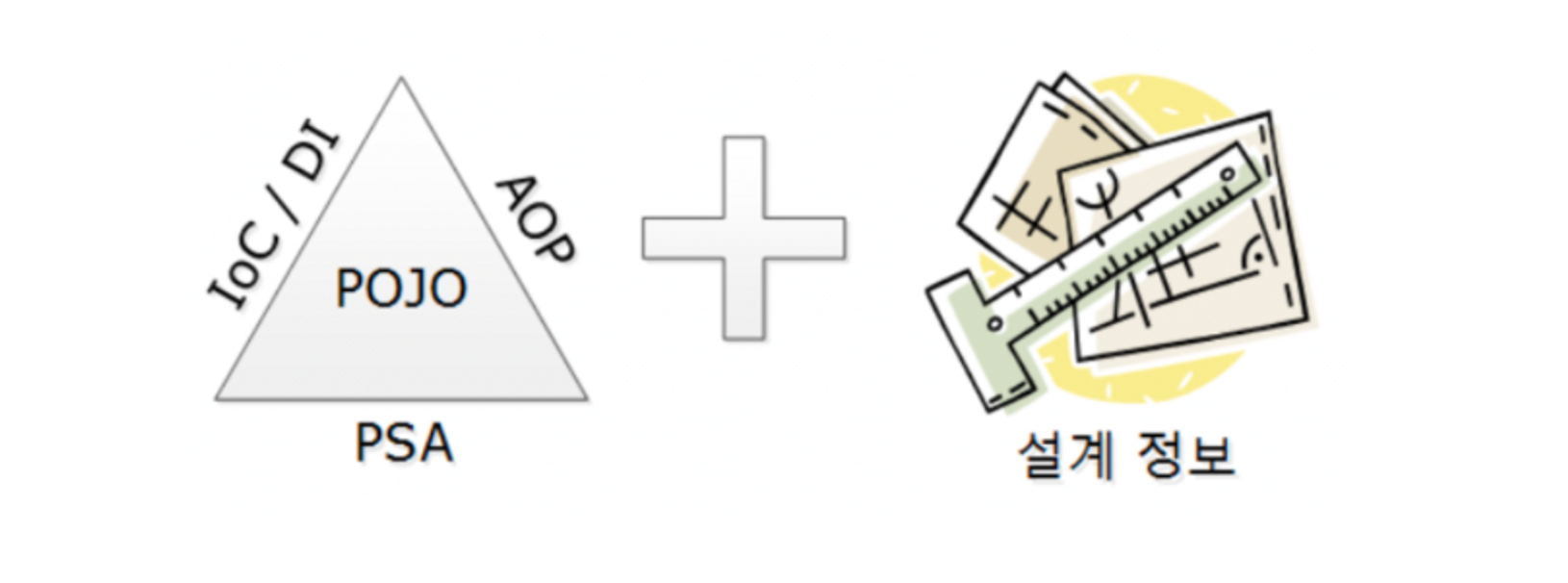
DI는 이전 포스팅에서 알아보았는데요. DI를 사용하면 하위 타입에 따라 달라지는 로직으로부터상위 객체를 협력 흐름을 추상화할 수 있습니다. 스프링은 어떤 구현체를 사용할 것인지 그 정보를 애노테이션을 달아두면 스프링부트 애플리케이션이 뜰때 이 정보를 스캔해서 스프링 컨테이너에 등록해둡니다. 애플리케이션이 동작하면서 의존성 주입이 필요하면 스프링 컨테이너가 주입을 담당합니다.
서비스 추상화는 비즈니스 로직이 있는 서비스 계층으로부터 기술적인 복잡성을 숨기는데요, 예를 들어 서비스 추상화를 사용하는 예시로 트랜잭션 매니저가 있습니다. 애플리케이션이 사용하는 데이터베이스의 종류나 Jdbc나 Jpa 등의 데이터 액세스 기술은 바뀔 수 있습니다. 이러한 변화가 비즈니스 로직을 바꾸지 않도록, 트랜잭션을 사용하는 일관된 API를 제공하는 것이 트랜잭션 매니저입니다.
AOP는 많은 비즈니스 로직에 공통으로 적용되는 로깅과 같은 부가기능을 한군데에 작성해놓고 여러 비즈니스 로직에 재사용하는 방법을 말합니다. 참고로 DI는 서비스 추상화, AOP, 비즈니스 로직에서 공통적으로 사용하는 스프링의 기본적인 객체지향 기법입니다.
위의 내용은 발표 주제를 벗어나기 때문에 다루지는 않지만요, 스프링에서 중요한 개념들이기 때문에 저의 블로그 링크 글을 남겨두겠습니다. ㅎㅎㅎㅎ
- 의존성 주입 : https://minforbackup.tistory.com/entry/DI와-IoC의-차이는-무엇이고-스프링-컨테이너는-무엇을-지원하는가
- 서비스 추상화 : https://minforbackup.tistory.com/entry/트랜잭션-개선-과정-분석-feat-서비스-추상화-책임-주도-접근법
- AOP : https://minforbackup.tistory.com/entry/스프링-AOP
아래 코드는 스프링부트로 웹 애플리케이션을 만들 때 자주 접하는 코드입니다. DI는 보통 생성자를 통해 이루어지는데, 롬복의 @RequiredArgsConstructor을 사용하면 final 필드를 초기화하는 생성자를 만들어주기 때문에 깔끔한 코드로 생성자 주입이 가능합니다.
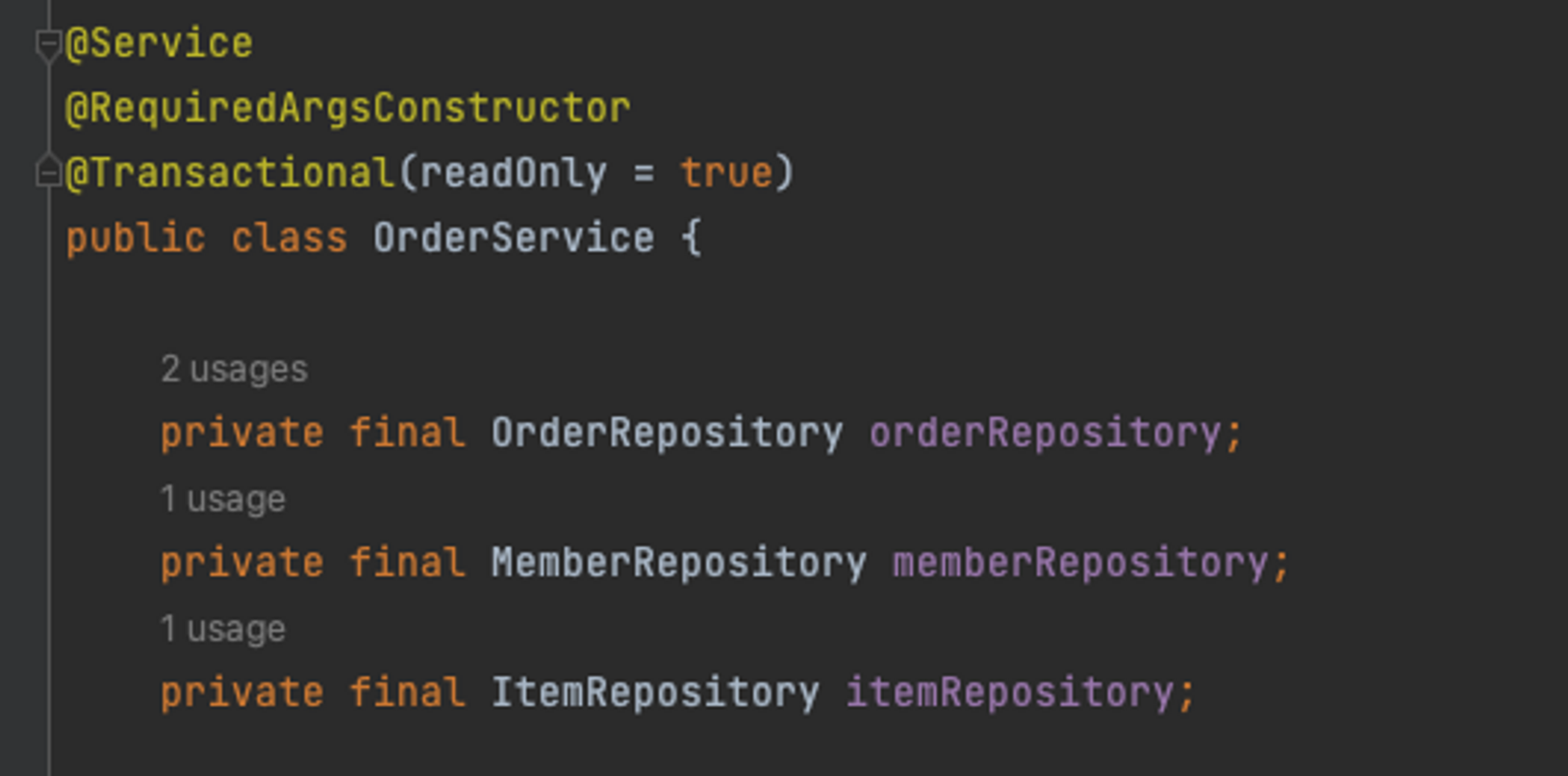
스프링 컨테이너를 사용해 DI를 받을 때 조심해야하는 부분이 있습니다. 스프링 컨테이너는 기보적으로 등록된 빈을 싱글톤으로 관리합니다. 싱글톤은 프로그램에서 딱 하나만 존재하는 오브젝트로, 전역객체이기 때문에 다른 객체에 의해 접근되어 강한 결합도를 가지기 쉽습니다. 그래서 싱글톤은 불안정한 구현 정보인 상태를 가지면 안됩니다. 스프링 컨테이너로 등록할 빈은 반드시 읽기 전용 변수나 싱글톤 타입만을 필드로 가지며, 상태 변화를 유발해야하는 경우 메소드의 매개변수로 주입받아 메소드 안에서만 다른 객체의 상태 변화 메시지를 요청해야 합니다.
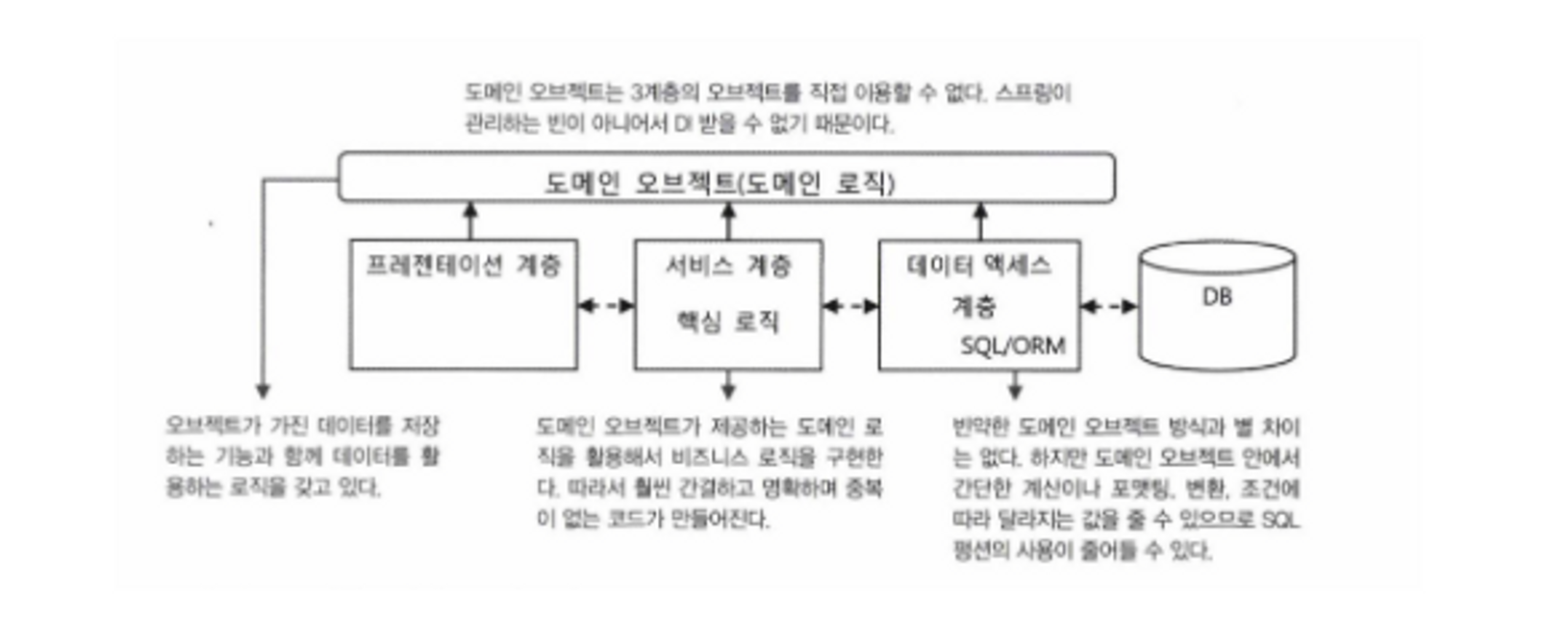
다음으로 스프링 애플리케이션을 개발할 때 필요한 지식을 알아보겠습니다. 웹 애플리케이션은 주로 세개의 계층으로 구성(3 tier application)합니다. 데이터 액세스 계층, 서비스 계층, 프레젠테이션 계층으로 나뉩니다. 데이터액세스는 말 그대로 DB나 메인 프레임, 외부 시스템을 통해 데이터를 얻어오는 계층을 말합니다. 기술적인 복잡성을 위해 수직적으로 구성하여 추상화 레이어를 도입하기 도합니다. 서비스 계층에서는 비즈니스 로직을 담고, 이상적인 POJO로 작성합니다. 프레젠테이션 계층은 요청의 매핑이나 바인딩, 클라이언트에 넘겨줄 화면, MVC 계층을 포함하여 웹 클라이언트와의 상호작용을 담당합니다. 이러한 계층은 애플리케이션의 규모에 따라 하나로 합칠 수도 있고, 다른 계층을 추가적으로 두는 것도 가능합니다.
중요한 것은 각 계층은 다른 계층을 침범하면 안됩니다. 자신의 역할과 기술에만 충실한 계층을 만들아야 각 계층 사이의 결합도는 낮아지고, 각 계층의 응집도는 높아집니다. 객체지향에서 오브젝트 단위로 적용했던 방법을 애플리케이션 계층으로 확장해서 동일한 논리를 적용합니다. 예를 들어, 이런 코드는 데이터 액세스 계층과 서비스 계층이 종속되게 합니다. 서비스 계층이 DAO를 호출할 때 사용하도록 정의한 인터페이스 메소드인데, 리턴 타입인 ResultSet과 예외인 SQLException은 JDBC에 종속적이어서, 데이터 액세스 기술을 JDBC가 아닌 다른 기술로 변경하면 서비스 인터페이스까지 영향을 줍니다. 그러므로 데이터 액세스 계층에 종속되지 않는 반환 타입인 List와 스프링이 추상화해주는 DataAccessException를 사용해야 합니다.
// 데이터 액세스 계층에 종속적 : ResultSet, SQLExcpetion
public ResultSet findUsersByName(String name) throws SQLException;
// 종속적이지 않음 : List와 스프링이 추상화한 예외
public List<User> findUsersByName(String name) throws DataAccessException;
3 tier로 이루어진 애플리케이션의 계층 사이에 돌아다니는 정보를 취급하기 위한 방법으로, 데이터를 추상화한 도메인을 사용하는 도메인 중심의 아키텍처를 사용해야 합니다. SQL을 사용해 가져온 오브젝트는 처음 봤던 자료구조 클래스와 다름이 없습니다. 이 클래스가 애플리케이션 안에서 사용되는 맥락을 고려해 비즈니스 메소드를 추가하여 도메인으로 만들고, 각 계층에서 이러한 도메인을 일관되게 사용하도록 해야 합니다.
다음 게시글에서는 이전에 만든 카페 예제를 스프링의 웹 애플리케이션으로 확장해보겠습니다.
'OOP > <객체지향과 스프링의 이해>, by me' 카테고리의 다른 글
| [객체지향과 스프링의 이해] 7. 마치며 (0) | 2023.05.30 |
|---|---|
| [객체지향과 스프링의 이해] 6. 카페 코드를 스프링 웹 애플리케이션으로 만들기 (0) | 2023.05.30 |
| [객체지향과 스프링의 이해] 4. 카페 코드에 다형적인 결제 협력 추가하기 (0) | 2023.05.30 |
| [객체지향과 스프링의 이해] 3. 객체지향 이해하기 (0) | 2023.05.30 |
| [객체지향과 스프링의 이해] 2. 카페 코드를 객체지향적으로 개선하기 (0) | 2023.05.30 |


