서버리스 아키텍처를 구성하던 중 서버리스 데이터베이스인 DynamoDB를 알게 되었다. 인물 퀴즈 백엔드 API에 적용하고자 DynamoDB에 대해서 조사해보았는데, 안타깝지만 내가 원하는 사용 패턴과 DynamoDB의 접근법이 달라서 도입할 수 없었다. 어쨌든 DynamoDB를 조사하면서 이 서비스가 어떤 장점이 있고, 어떤 유즈 케이스에 도입하면 좋을지, 키를 어떻게 설계해야할지 알아본 내용을 정리한다.
DynamoDB란?
DynamoDB는 AWS가 제공하는 서버리스 기반의 NoSQL 데이터베이스이다. Key Value 스키마를 제공한다. Key Value는 조인 연산이 필요한 RDS의 스키마보다 더 유연하고 빠른 조회를 지원한다. (NoSQL과 RDS 스키마는 그 기반이 다르다. CPU 최적화 vs 메모리 최적화)
AWS에서 소개되는 서버리스 아키텍처에서 데이터베이스가 필요한 부분에는 대부분 DynamoDB가 있다. 아래 아키텍처는 DynamoDB와 람다를 사용해 실시간 데이터 분석을 지원한다.
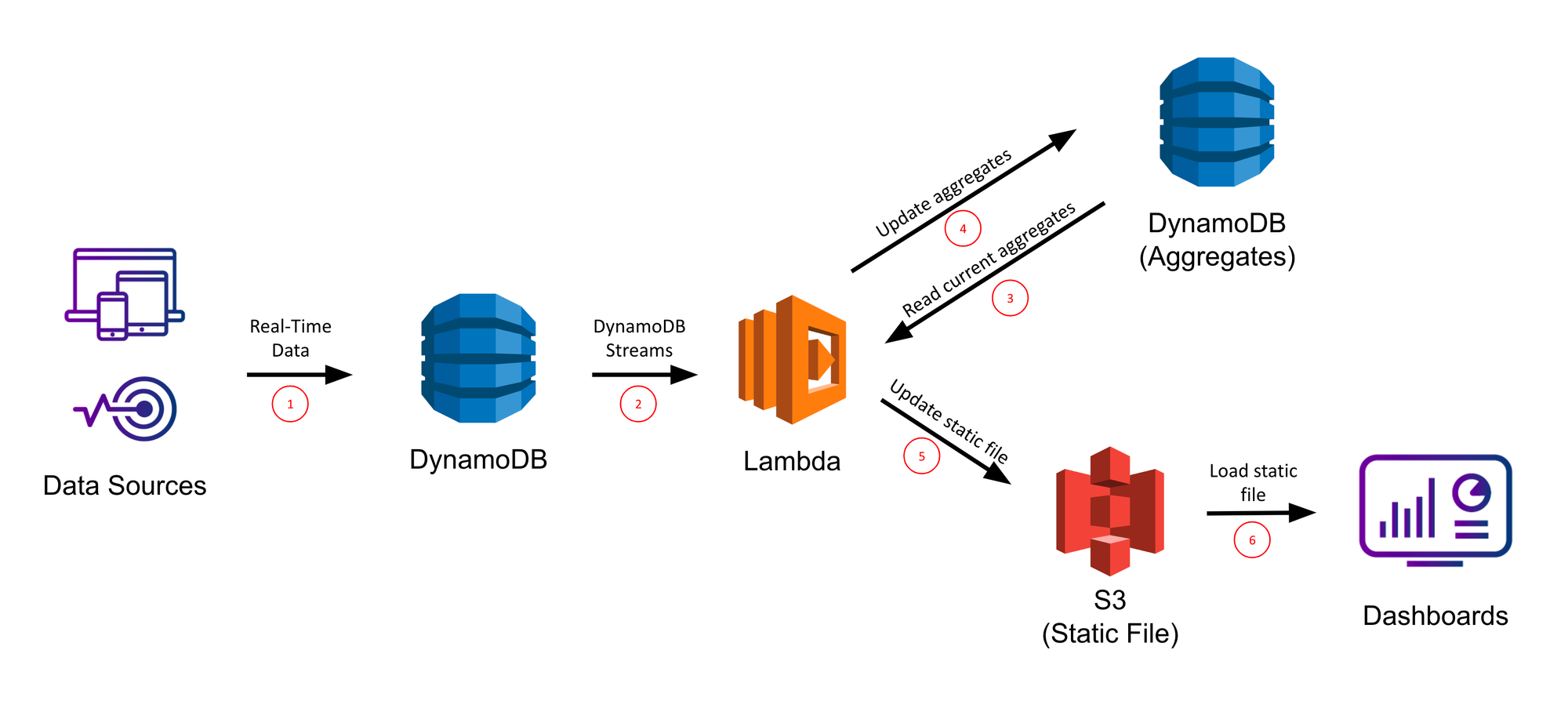
DynamoDB의 특징
NoSQL 데이터베이스 | 데이터 관리 | Amazon Web Services
NoSQL 데이터베이스 | 데이터 관리 | Amazon Web Services
닫기 이 다이어그램은 Amazon DynamoDB의 핵심 기능과 기타 AWS 서비스와의 통합을 보여줍니다. 왼쪽에서 오른쪽으로 3개의 섹션이 표시되어 있습니다. 첫 번째 섹션에는 DynamoDB 서비스 아이콘 그림이
aws.amazon.com
DynamoDB의 소개 페이지를 보면 다음과 같은 장점이 있다.
- 일관적인 10밀리초 미만의 성능, 거의 무제한의 처리량, 다중 리전 자동 복제
- 암호화, 자동 백업 및 복원, 최대 99.999% 가용성
- 오토 스케일링을 지원하는 완전 관리형 서버리스 데이터베이스, 운영 부담 없음 (반면 CI/CD가 어렵다)
- 다른 AWS 서비스와 통합
블로그의 포스팅과 사용 경험 공유에서 찾은 단점은 다음과 같다.
- 비싼 비용. 빠르게 늘어나는 데이터 세트에 대해 비용 폭탄 발생! 캐싱, 보조 인덱스 유료, 비싼 읽기 및 쓰기 비용, 핫 파티션 발생 시 오버 프로비저닝으로 인한 비용 증가
- 쿼리에 대한 트랜잭션이 없다.
- 데이터의 관계 연산 없이 탐색한 값을 바로 가져오므로 데이터 중복 발생. 중복되는 데이터에 쓰기 연산 시 일관성 맞추기 위한 추가 작업이 필요하다.
DynamoDB 유즈 케이스와 구성
DynamoDB는 무한에 가깝게 많은 데이터를 몇가지 키의 조합으로 빠르게(밀리초) 선택하는 것을 매우 잘한다. AWS 한국 블로그에서 소개된 DynamoDB 사용 사례에 따르면, 매우 많은 데이터를 생성하면서 일관적인 응답 시간을 유지해야하는 글로벌 게임 회사에서 플레이어 데이터, 세션 데이터, 리더 보드 등을 DynamoDB로 관리한다. (반면 CPU 집약적인 집계쿼리, 대량의 range 쿼리, full text search는 잘 못함)
DynamoDB는 어떻게 이렇게 빠르고 일관된 응답시간을 제공할까? 그 이유는 데이터를 저장하는 구조를 보면 알 수 있다. (이미지 출처 : https://zuminternet.github.io/DynamoDB/)
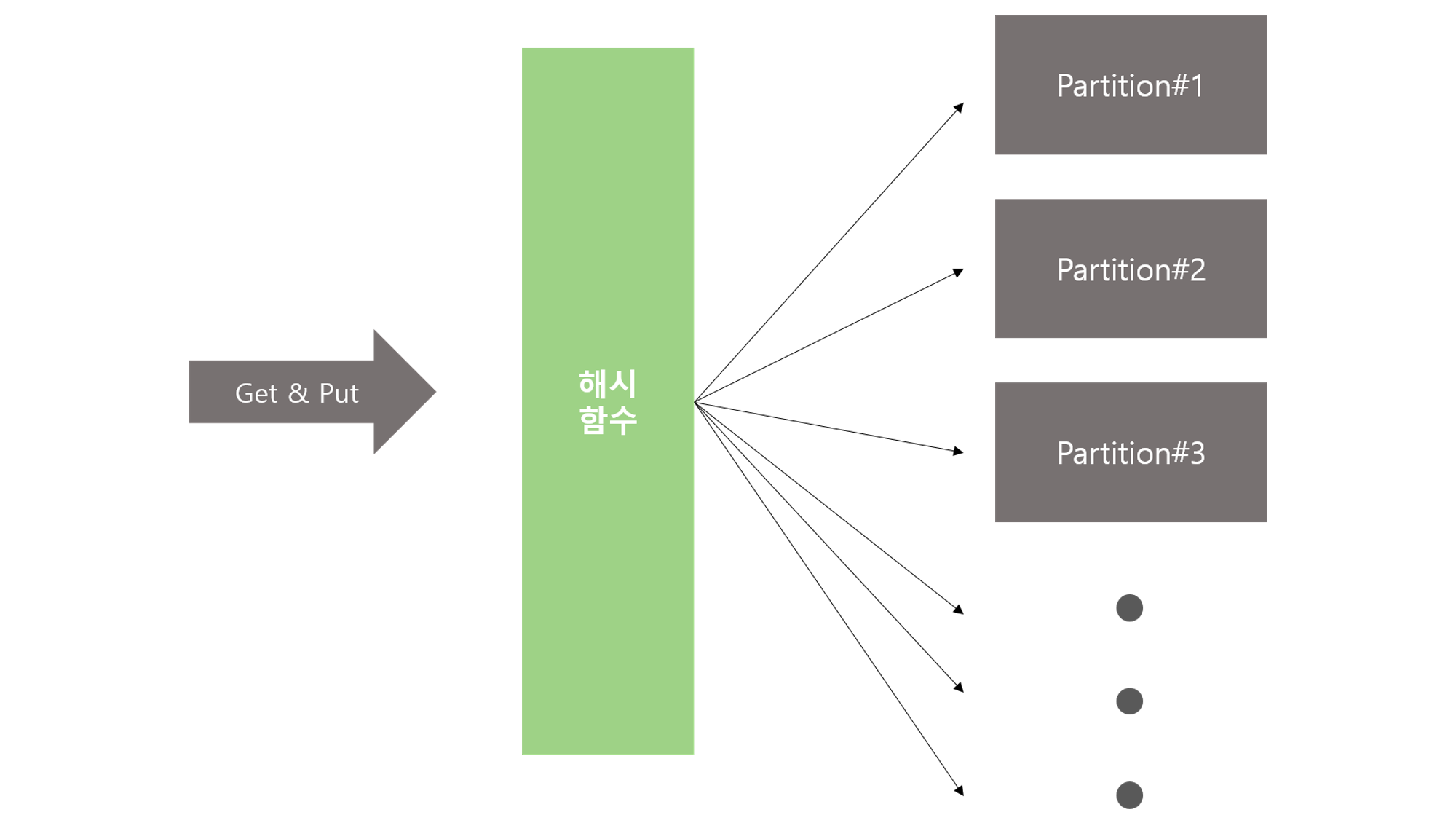
DynamoDB에서 Table은 논리적인 저장 단위이고, Partition은 물리적인 저장 단위이다. DB를 사용하면서 읽기나 쓰기 작업은 물리적인 단위인 Partition에서 이루어지므로 빠르게 Partition을 찾을 수 있어야 한다. DynamoDB는 데이터가 저장된 위치를 빠르게 찾기 위해, 데이터를 해시 함수에 돌려서 나온 값으로 Partition을 할당한다. 테이블이 아무리 커지더라도 해시 값을 사용해 빠른 속도로 해당 데이터에 접근할 수 있는 것이다.
그렇다면 해시함수에 넘겨야하는 각 데이터의 필드는 무엇일까? 이 데이터를 Partition Key라고 부른다. Partition Key를 잘 설계해서 Partition에 고르게 요청이 갈 수 있도록 해야 한다.(Hot Partition 방지) 또한 데이터를 빠르고 정확하게 찾기 위해 다른 키들을 적절히 조합해서 사용할 수 있어야 한다.
Key Value 스토어에 저장되는 데이터
DynamoDB의 키 디자인에 대해 알아보기 전에, DynamoDB에 저장되는 데이터의 모양을 살펴보자.
NoSQL의 스키마는 RDB의 스키마와 확연하게 다른데, 그 이유는 각 데이터베이스의 기반 배경이 다르기 때문이다. RDB는 CPU보다 메모리가 비싼 시절에 나왔기 때문에, 스키마도 메모리를 덜 사용하고 CPU를 더 사용하는 전략을 택했다. 테이블에 중복이 없도록 정규화하고, 조인 연산으로 데이터를 조회하는 이유도 메모리를 덜 사용하기 위함이다. 반면 NoSQL이 나왔을 때는 메모리보다 CPU가 더 비싸다.(메모리 값이 더 큰 폭으로 하락했다) 따라서 데이터를 중복되게 저장하되, 조인과 같이 CPU를 많이 먹는 연산 없이 바로 픽해서 가져오는 전략을 취했다. 이를 이해하고 나면 NoSQL의 데이터가 왜 저렇게 생겼는지 이해가 가기 시작한다.
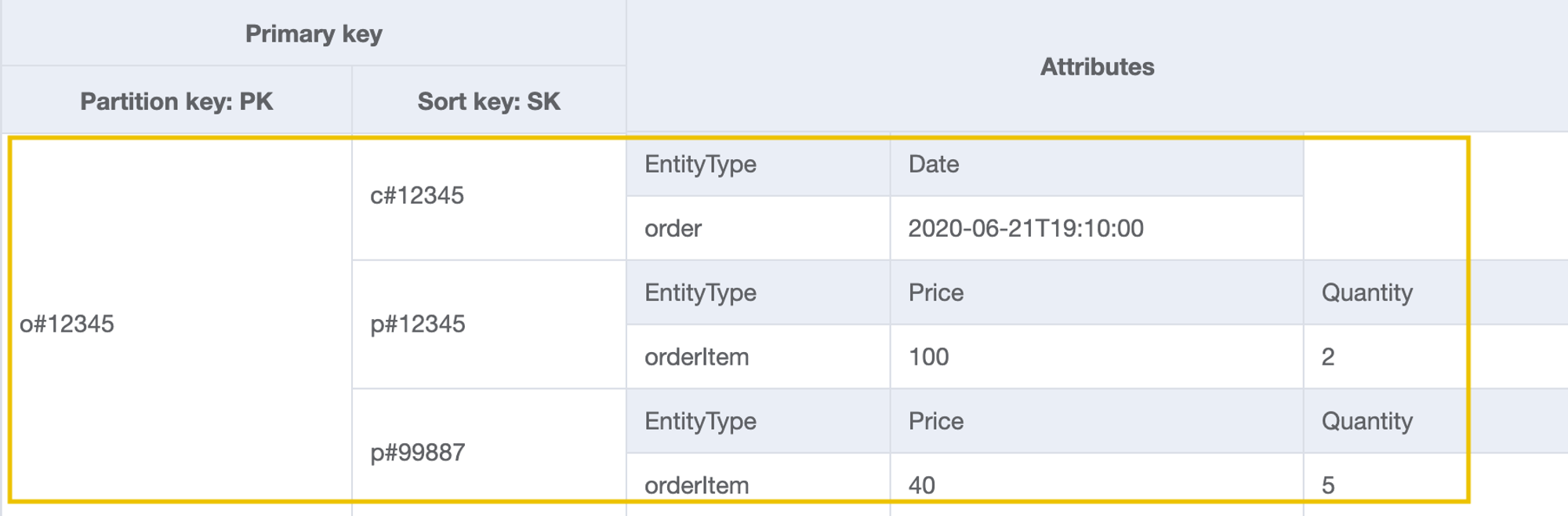
위의 이미지는 DynamoDB를 온라인 상점의 데이터 스토어로 사용하는 튜토리얼에서 액세스 패턴인 getOrderDetailsByOrderId와 getProductByOrderId를 처리하기 위해 설계한 스키마이다. 파티션을 결정하는 PK는 o#12345(Order#오더아이디라고 생각하면 됨)이다. 옆에 보이는 세개의 데이터들이 가까운 물리적 위치에 저장된다. Sort Key를 보면 c#12345(Customer), p#12345, p#99887(Product)가 보이는데, 이는 o#12345와 관련된 customer, product 정보를 가지는 것이다.
위의 데이터 스키마는 o#12345와 관련된 모든 데이터를 표현한다. 만약 o#12345와 관련된 데이터를 모두 가져오고 싶다면 PK=orderId를 사용하여 조회하면 되고, 오더와 관련된 product 데이터만 가져오고 싶다면 PK=orderId에 SK=p#를 사용해 쿼리하면 된다. 정렬 키에 #을 추가해 계층적인 키를 표현할 수도 있고, 추가적인 필터링이 필요하다면 보조 인덱스를 사용하면 된다.
ERD를 설계했다면 Order, Product, Customer은 다른 테이블로 정규화되어 조인 연산으로 함께 조회해왔겠지만, NoSQL는 스키마를 비정규화하여 관련된 데이터를 한번에 저장해버린다. 따라서 모든 데이터의 액세스 패턴을 알고 이 패턴에 따라 스키마를 정의하는 것이 중요하다. 중복되는 데이터가 늘어나더라도 연산 비용이 적기 때문에 빠르게 응답할 수 있다. 물론 데이터가 중복되기 때문에 특정 데이터를 수정하거나 관련 있는 데이터를 모두 삭제하는 연산은 복잡하다.

DynamoDB의 키 종류
Primary Key
기본 키는 테이블의 각 항목을 나타내는 고유 식별자로, Partition Key와 Sort Key로 구성된다.
PK (Partition Key)
- 내부 해시 함수의 입력으로 사용하는 값, 필수 입력
- 해시 함수 출력에 따라 항목을 저장할 파티션(물리적 스토리지)가 결정됨
- 파티션에는 1K WCU, 3K RCU, 10 GB의 제약조건이 있으므로, 카디널리티가 높은 항목을 PK로 골라야 한다. 가령 아이템의 Id 값 등
SK (Sort Key)
- 파티션 내부에서 정렬되는 기준으로 사용하는 값, 선택 입력
- 범위 조회를 지원하므로, 더 유연한 조회가 필요할 때 사용하는 키
- 예를 들어 특정 가수의 특정 노래들을 조회하고 싶다면, PK는 artistId로 놓고 SK는 songId로 놓으면 됨
- 정렬 키는 선택 및 범위 연산이 가능하므로, 데이터를 계층적으로 설계해 해당 계층에 맞는 데이터를 가져올 수 있음. 복합 정렬 키라고 부름.
Secondary Index
PK와 SK의 조합만으로 데이터에 액세스하기 어려운 경우가 많다. 저장된 데이터 항목을 기준으로 데이터 항목을 쿼리하고 싶은 경우, 보조 인덱스를 생성해서 테이블을 쿼리한 방법대로 인덱스를 쿼리한다. 참고로 DynamoDB의 인덱스 생성 비용은 유료이고, 그만큼 리소스를 더 사용하므로 가급적이면 보조 인덱스 사용을 줄이는 것이 좋다.
보조 인덱스도 PK와 SK로 구성하며, RDB와 마찬가지로 별도의 메모리에 정렬된 데이터를 관리한다.
LSI
- 기본 테이블로부터 로컬 보조 인덱스를 생성
- 기본 테이블과 동일한 Partition Key를 사용, 원하는 필드 Sort Key 지정
- 용량은 10GB로 제한, 테이블 생성 시에만 생성 가능하며, 삭제 불가능 → 사용 지양
- Eventual Consistent Read와 Strong Consistent Read 선택 가능 → 데이터의 정합성이 중요하다면 사용
- 파티션 내 테이블 데이터와 함께 저장
GSI
- Partition Key를 필수 설정하고, Sort Key는 선택 사항
- 용량 제한 없음, 테이블 생성 후에도 생성/삭제 가능 → 사용 권장!!
- 테이블 외 인덱스 데이터 따로 저장
- Eventual consistent read만 가능
키 사용 유형에 따른 테이블 모습
PK만 사용
- 단순 기본 키만 사용하여 액세스
- PK 값으로 해시하여 일차하는 데이터를 모두 가져옴
- 모든 항목의 PK 값이 달라야함
- 예시 : 스키마가 다르더라도 PersonId(PK)가 일치하는 데이터 조회
- { "PersonID": 101, "LastName": "Smith", "FirstName": "Fred", "Phone": "555-4321" } { "PersonID": 102, "LastName": "Jones", "FirstName": "Mary", "Address": { "Street": "123 Main", "City": "Anytown", "State": "OH", "ZIPCode": 12345 } } { "PersonID": 103, "LastName": "Stephens", "FirstName": "Howard", "Address": { "Street": "123 Main", "City": "London", "PostalCode": "ER3 5K8" }, "FavoriteColor": "Blue" }
PK + SK 사용
- PK의 해시 함수 출력에 따라 파티션을 결정하고, 파티션 값이 동일한 모든 항목은 SK를 기준으로 정렬되어 물리적으로 가까운 위치에 저장됨
- 항목에 액세스할 때는 PK로 파티션을 픽하고, SK로 범위를 결정함.
- 예시 : PK Artist로 파티션을 찾고, 그 안에서 SK인 SongTitle로 액세스 범위 지정
- { "Artist": "No One You Know", "SongTitle": "My Dog Spot", "AlbumTitle": "Hey Now", "Price": 1.98, "Genre": "Country", "CriticRating": 8.4 } { "Artist": "No One You Know", "SongTitle": "Somewhere Down The Road", "AlbumTitle": "Somewhat Famous", "Genre": "Country", "CriticRating": 8.4, "Year": 1984 } { "Artist": "The Acme Band", "SongTitle": "Still in Love", "AlbumTitle": "The Buck Starts Here", "Price": 2.47, "Genre": "Rock", "PromotionInfo": { "RadioStationsPlaying": { "KHCR", "KQBX", "WTNR", "WJJH" }, "TourDates": { "Seattle": "20150622", "Cleveland": "20150630" }, "Rotation": "Heavy" } } { "Artist": "The Acme Band", "SongTitle": "Look Out, World", "AlbumTitle": "The Buck Starts Here", "Price": 0.99, "Genre": "Rock" }
PK + SK + GLI 사용
- 키가 아닌 속성에 대한 쿼리 속도를 높이기 위해 글로벌 보조 인덱스를 사용함.
- 보조 인덱스도 테이블처럼 별도의 메모리를 사용하므로, 가능한 사용을 최소화하는 것이 좋다. 보조 인덱스를 만들 때 PK와 SK를 지정하며, 이때 원본 테이블과 동일한 키 스키마를 가질 필요는 없다.
- 예시 : PK UserId, SK Game Title인 테이블에서 게임 별 최고점수를 가진 유저 아이디 조회
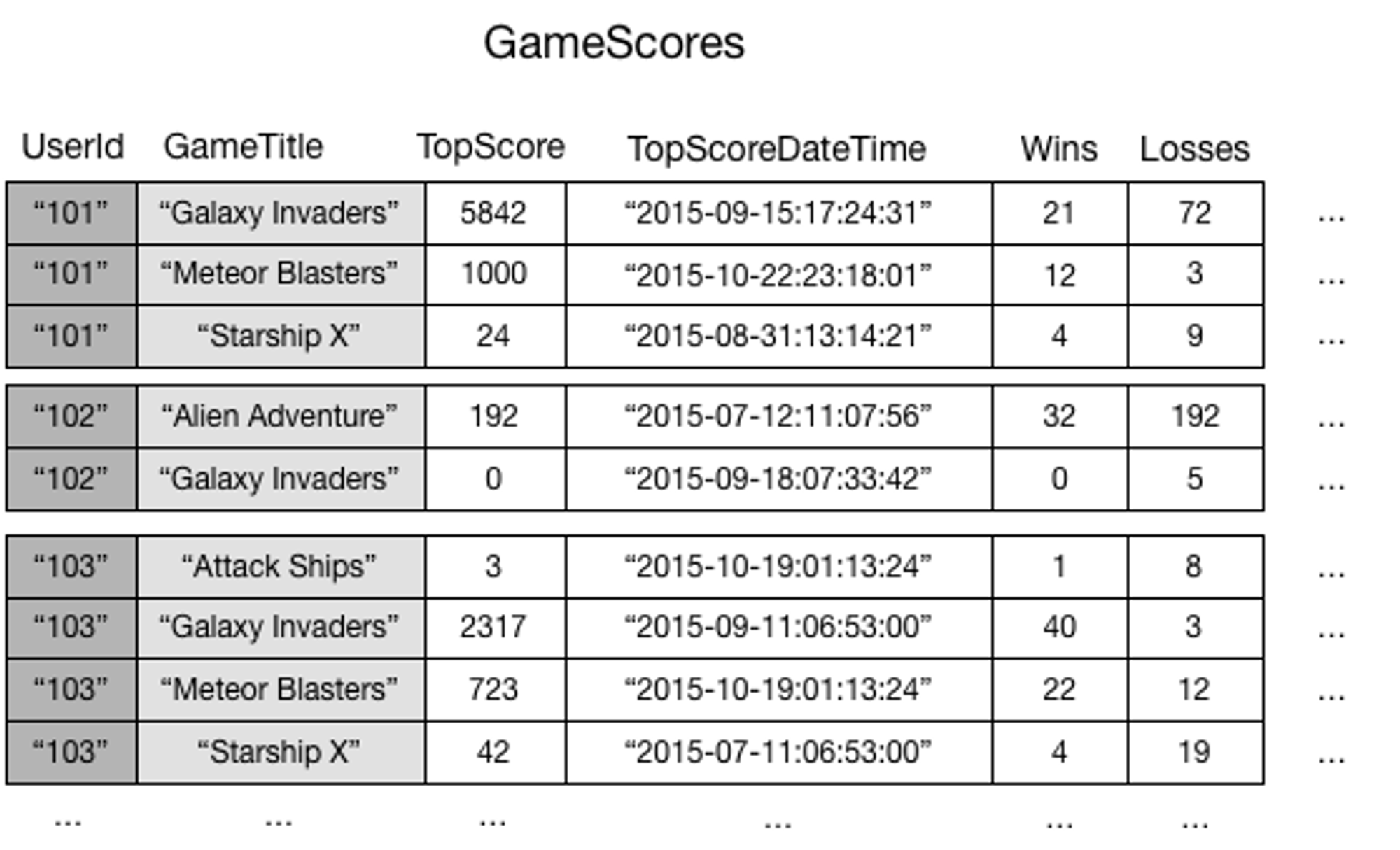
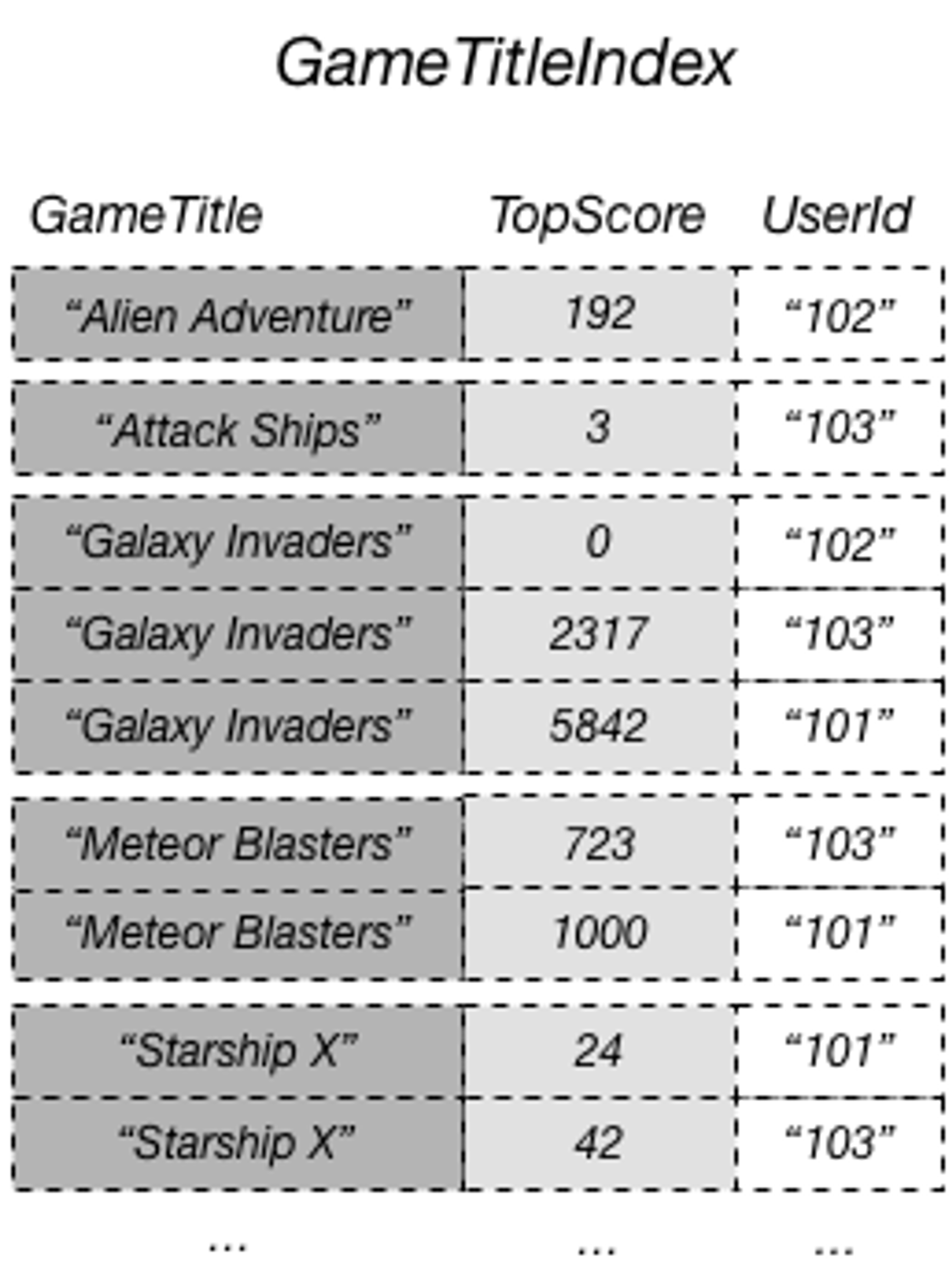
DynamoDB의 키 디자인 & 싱글 테이블 디자인
싱글 테이블 디자인
- 모든 엔티티를 하나의 테이블로 설계하는 방법
- 장점 : 적은 운영 부담, 높은 성능 및 쓰로틀링 경감
- 단점 : 높은 러닝 커브, 시계열 데이터나 엔티티별로 다른 액세스 패턴을 갖는다면 적합하지 않음
테이블 디자인의 안티 패턴
- PK를 UserID로 고정하고 시작하는 습관 : 대량 트래픽을 유발하는 헤비 유저 고민
- 엔티티 별로 테이블을 만드는 습관 : 관리 부담
- GSI를 많이 사용하려는 습관 : 유료입니다.
키 디자인 풀 사이클
- 비즈니스 유스 케이스 이해하기 : DynamoDB 도입이 적절한지 판단
- ERD 그리기 : 도메인 간의 관계 정의하기, 속성을 상세하게 서술할 필요 없음
- 모든 데이터 액세스 패턴 정리하기 : 데이터 액세스 패턴이 자주 변경되는 스타트업이라면 RDB로 시작하는 것을 권장
- 키 디자인 시작하기 : https://github.com/aws-samples/amazon-dynamodb-design-patterns/tree/master/examples/an-online-shop
비즈니스 유스 케이스 이해
- customer가 온라인 상점을 방문하여 다양한 제품을 검색하고 제품 일부를 주문합니다.
- ~~invoice를 기준으로 할인코드 또는 기프트카드로 결제하고 남은 금액은 신용카드로 결제할 수 있습니다.~~
- 구매한 제품은 1개 또는 여러개의 창고에서 선택하여 제공된 주소로 배송됩니다.
ERD 그리기
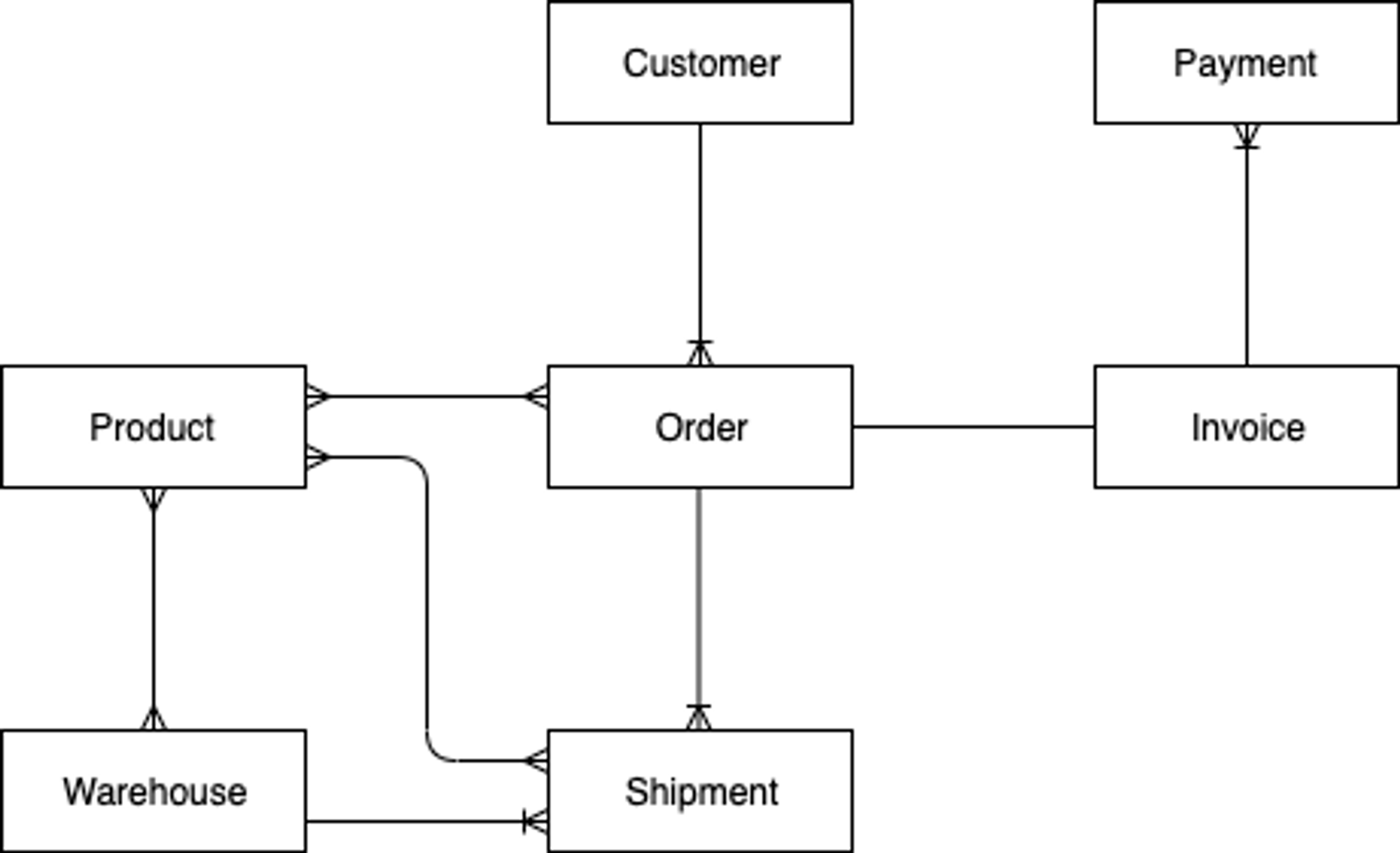
데이터 액세스 패턴 정리
| # | 액세스 패턴 |
| 1 | Get customer for a given customerId |
| 2 | Get product for a given productId |
| 3 | Get warehouse for a given warehouseId |
| 4 | Get a product inventory for all warehouses by a productId |
| 5 | Get all order details for a given orderId |
| 6 | Get all products for a given orderId |
| 7 | Get invoice for a given orderId |
| 8 | Get all shipments for a given orderId |
키 디자인 시작하기
| # | Access Patterns | Table/GSI/LSI | Key Condition | Filter Expression | Example |
| 1 | Get customer for a given customerId | Table | PK=customerId and SK=customerId | - | PK="c#12345" and SK="c#12345" |
| 2 | Get product for a given productId | Table | PK=productId and SK=productId | - | PK="p#12345" and SK="p#12345" |
| 3 | Get warehouse for a given warehouseId | Table | PK=warehouseId and SK=warehouseId | - | PK="w#12345" and SK="w#12345" |
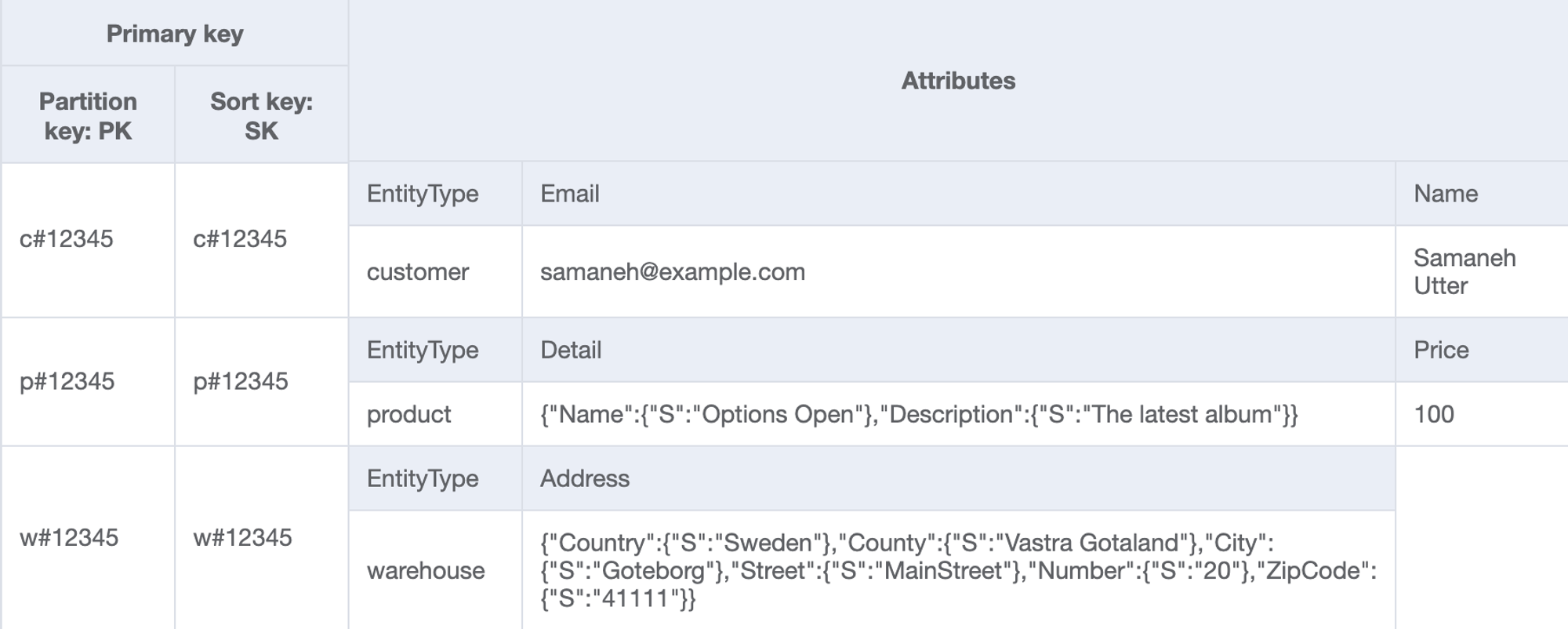
- 싱글 테이블은 여러 엔티티가 들어가므로 PK나 SK 자체를 고유의 엔티티로 취급한다.
- 이 액세스 패턴은 PK만 필요로 하지만, 다른 액세스 패턴은 SK까지 필요로 하므로 같은 값으로 채워 넣었다.
- 엔티티 타입 정보는 향후 분석 시에 활용할 수 있다.
| # | Access Patterns | Table/GSI/LSI | Key Condition | Filter Expression | Example |
| 4 | Get a product inventory for all warehouses by a productId | Table | PK=productId and SK begins_with "w#" | - | PK="p#12345" and SK begins_with "w#" |
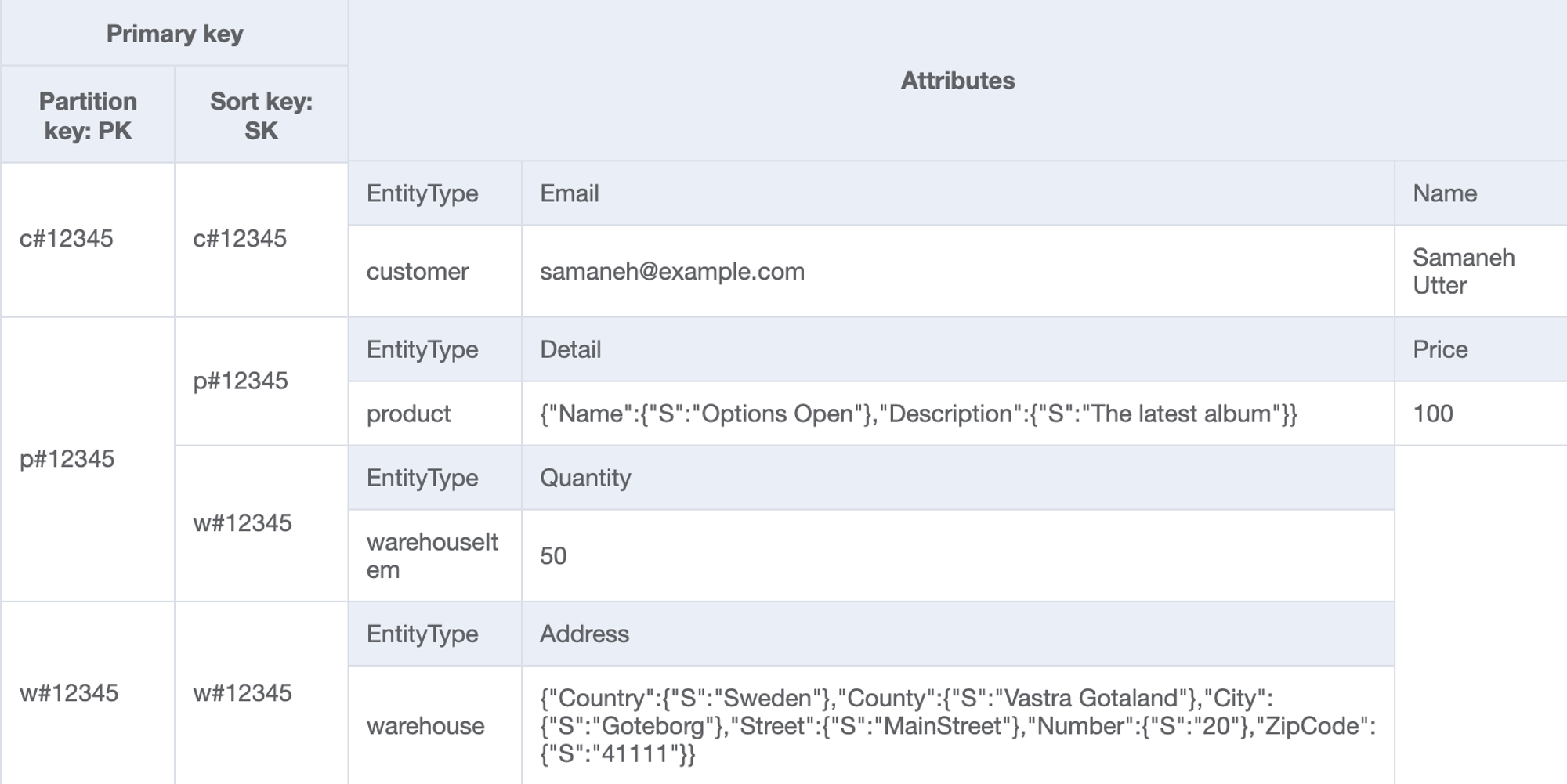
- p#12345는 w#12345에 50개만큼 저장되어있다.
- Dynamo DB는 실시간 조인 연산이 없다. PK와 SK로 모든 데이터를 단순히 끌어올리기만 하므로, 조회 패턴에 맞춰서 데이터를 저장해야한다.
| # | Access Patterns | Table/GSI/LSI | Key Condition | Filter Expression | Example |
| 5 | Get all order details for a given orderId | Table | PK=orderId | - | PK="o#12345" |
| 6 | Get all products for a given orderId | Table | PK=orderId and SK begins_with "p#" | - | PK="o#12345" and SK begins_with "p#" |
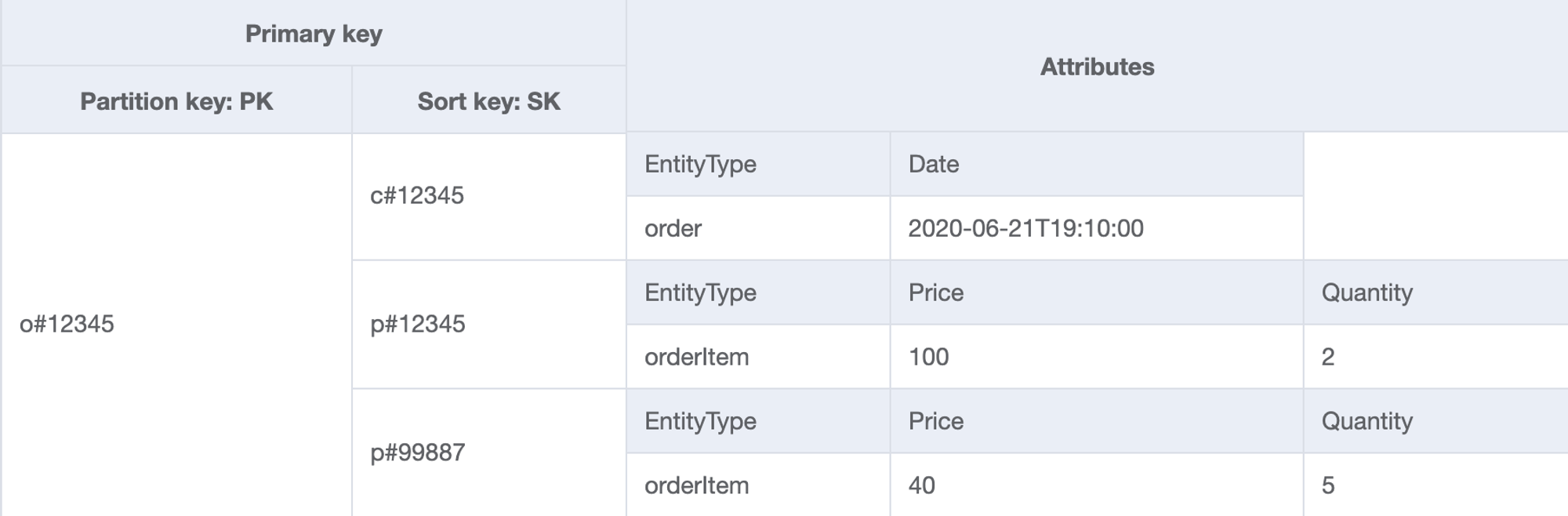
| # | Access Patterns | Table/GSI/LSI | Key Condition | Filter Expression | Example |
| 7 | Get invoice for a given orderId | Table | PK=orderId and SK begins_with "i#" | - | PK="o#12345" and SK begins_with "i#" |
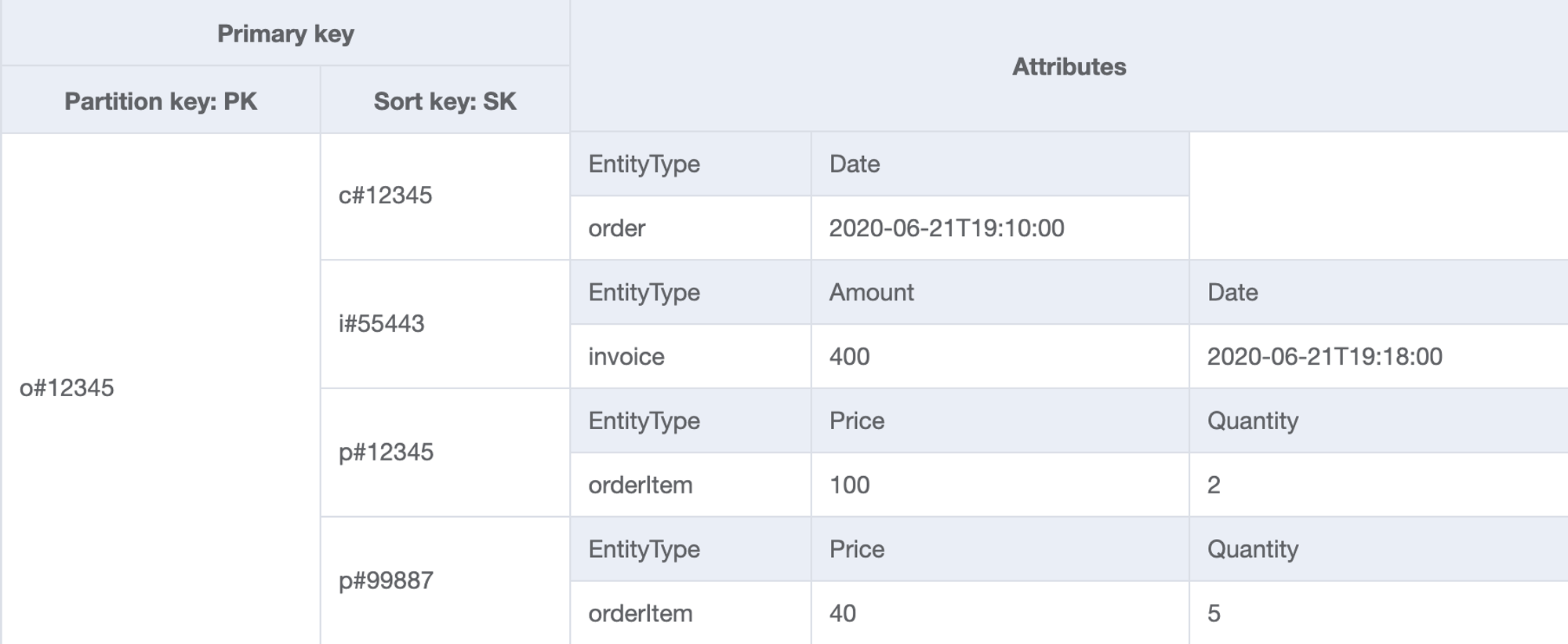
RDBMS로 관리했다면 order, customer, invoice, product를 조인해서 얻었을 결과이다. 반정규화한 데이터를 메모리에 그대로 저장해서 빠른 조회만 하는 것이 NoSQL의 특징!
| # | Access Patterns | Table/GSI/LSI | Key Condition | Filter Expression | Example |
| 8 | Get all shipments for a given orderId | Table | PK=orderId and SK begins_with "sh#" | - | PK="o#12345" and SK begins_with "sh#" |
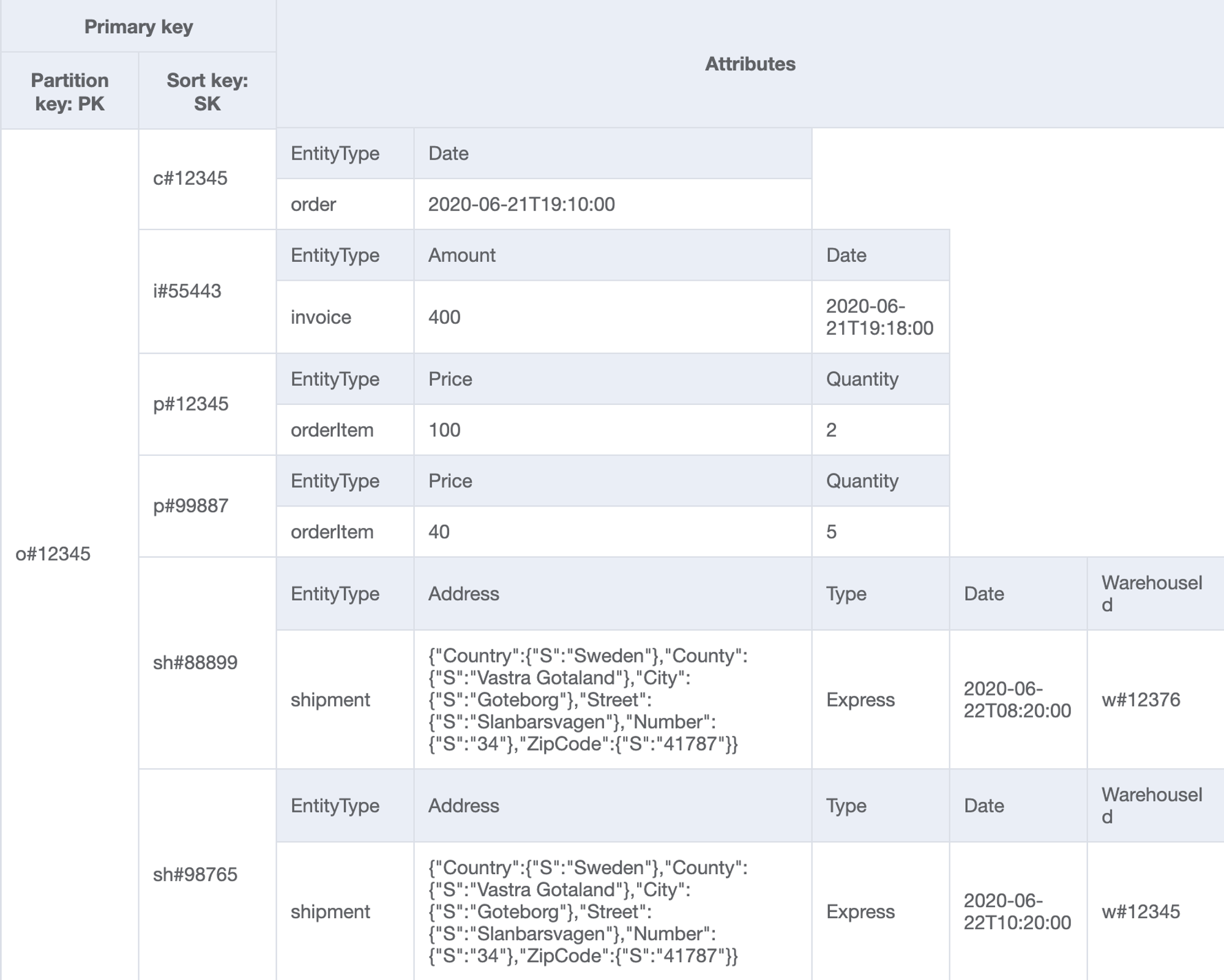
'Cloud > AWS' 카테고리의 다른 글
| json 데이터를 S3에 업로드하는 API 만들기 : With AWS API Gateway, Lambda, S3 (0) | 2024.01.17 |
|---|---|
| S3에 파일 업로드, 다운로드하는 public API 만들기 (0) | 2024.01.17 |
| [AWS Session 기록] 2200만 사용자를 위한 채팅 시스템 아키텍처 - 서호석 솔루션즈 아키텍트, AWS / 변규현 SW 엔지니어, 당근마켓 :: AWS Summit Korea 2022 (0) | 2024.01.17 |
| ELB + EC2 Auto Scaling (2) | 2024.01.07 |
| json 파일 업로드/다운로드하는 API 만들기 : AWS API Gateway, Lambda, S3 사용 (0) | 2023.12.24 |



